


总览
DeepSeek 是由深度求索公司推出的大语言模型。其中:
DeepSeek-V3 是在14.8万亿高质量 token 上完成预训练的一个强大的混合专家 (MoE) 语言模型,拥有6710亿参数。作为通用大语言模型,其在知识问答、内容生成、智能客服等领域表现出色。
DeepSeek-R1 是基于 DeepSeek-V3-Base 训练生成的高性能推理模型,在数学、代码生成和逻辑推断等复杂推理任务上表现优异。
DeepSeek-R1-Distill 是使用 DeepSeek-R1 生成的样本对开源模型进行微调得到的小模型,拥有更小参数规模,推理成本更低,基准测试同样表现出色。
支持的模型列表
|
模型名称
|
参数量
|
激活参数量
|
上下文窗口
|
推理资源推荐
|
|
DeepSeek-V3
|
671B
|
37B
|
128K
|
多机分布式部署,节点数量:2个,单节点配置:HCCPNV6 机型
|
|
DeepSeek-R1
|
671B
|
37B
|
128k
|
多机分布式部署,节点数量:2个,单节点配置:HCCPNV6 机型
|
|
DeepSeek-R1-Distill-Qwen-1.5B
|
1.5B
|
–
|
–
|
12C44GB 1卡A10
|
|
DeepSeek-R1-Distill-Qwen-7B
|
7B
|
–
|
–
|
12C44GB 1卡A10
|
|
DeepSeek-R1-Distill-Llama-8B
|
8B
|
–
|
128K
|
12C44GB 1卡A10
|
|
DeepSeek-R1-Distill-Qwen-14B
|
14B
|
–
|
–
|
16C96G 1卡A100
|
|
DeepSeek-R1-Distill-Qwen-32B
|
32B
|
–
|
–
|
32C192G 2卡A100
|
|
DeepSeek-R1-Distill-Llama-70B
|
70B
|
–
|
128K
|
164C948G 8卡A100
|
限时免费体验
平台限时免费开放 DeepSeek 模型的免部署在线体验,支持 DeepSeek-R1 和 DeepSeek-R1-Distill-Qwen-1.5B 两款模型,便于开发者直观比较“最大杯”和“最小杯”的性能差异。进入 DeepSeek 系列模型详情页面后,选择上方 Tab 即可进入在线对话体验页面。
对于其他模型,可按下方模型部署实践自主部署对应模型后体验。

模型部署实践
下文我们将选用尺寸相对最小的 DeepSeek-R1-Distill-Qwen-1.5B 模型进行部署实践。其他模型的操作流程类似,仅需注意算力资源的配置差异。
前置准备工作
模型:TI 平台已将 DeepSeek 模型内置在大模型广场中,您可直接选择模型并一键部署。
资源:1.5B 的 DeepSeek 模型对算力需求较小,单卡A10即可支持其推理服务。您有多种计费模式选择:
按量计费:对于仅需短时体验或所需算力较小的用户,机器来源推荐选用“从 TIONE 购买”,并选用“按量计费”模式。该模式无需提前准备算力。开始部署时,平台会自动分配资源并进行计费,本实践也将使用该模式进行展开。
包年包月:对于已购买 CVM 机器或需较大、稳定算力的用户,机器来源推荐选用“从 CVM 机器中选择”,并选择对应的资源组。该模式下需要您提前购买好 CVM 机器并添加至 TI 平台资源组,详细操作步骤请参考资源组管理。
步骤一:部署模型服务
2. 单击进入“DeepSeek 系列模型”卡片,查看模型详细介绍。
3. 在模型详情页面,单击新建在线服务,跳转至“模型服务 > 在线服务 > 创建服务”页面配置部署参数。
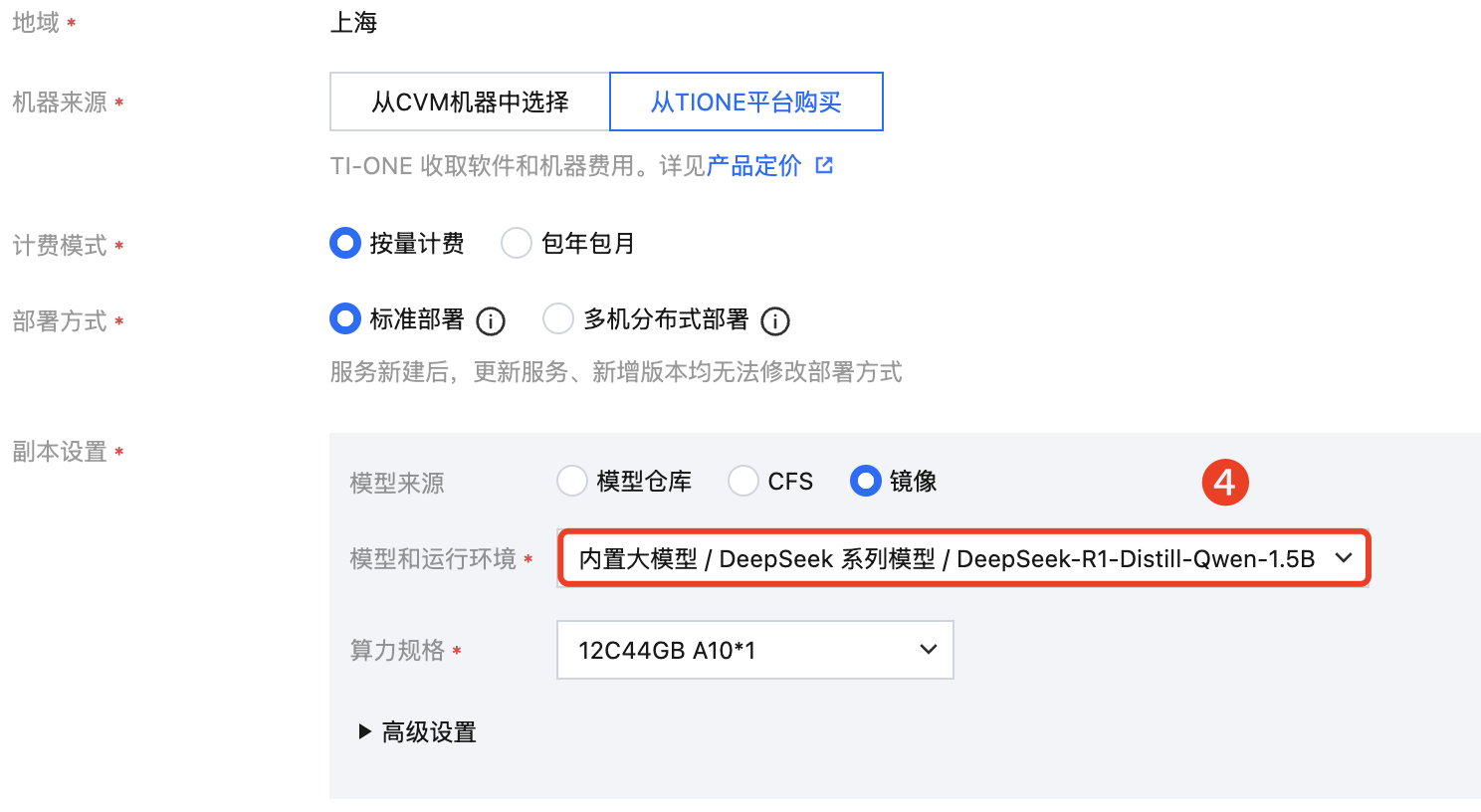
4. 按页面提示填写配置信息,参考如下:
服务名称:输入您的自定义的服务名称。如:“demo-DeepSeek-R1-Distill-Qwen-1_5B”。
机器来源:支持“从 CVM 机器中选择”和“从 TIONE 平台购买”两种模式。本例采用“从 TIONE 平台购买-按量计费”。如果您已购买自己的 CVM 机器,可以选择模式“从 CVM 机器中选择”。
部署方式:选择“标准部署”。
服务实例:
模型来源:选择 “镜像”类型。
模型和运行环境:选择“内置大模型/DeepSeek 系列模型/DeepSeek-R1-Distill-Qwen-1.5B”。
算力规格:12C44GB A10*1,推理资源配置建议详见大模型推理所需资源指南。
5. 授权并同意《腾讯云 TI-ONE 训练平台服务协议》,单击底部启动服务,正式发起服务部署。
步骤二:体验模型效果
1. 服务部署完成后,在“模型服务 > 在线服务”页面的列表中,其状态将显示为“运行中”。DeepSeek-R1-Distill-Qwen-1.5B 模型的部署时长预计为1-2分钟。
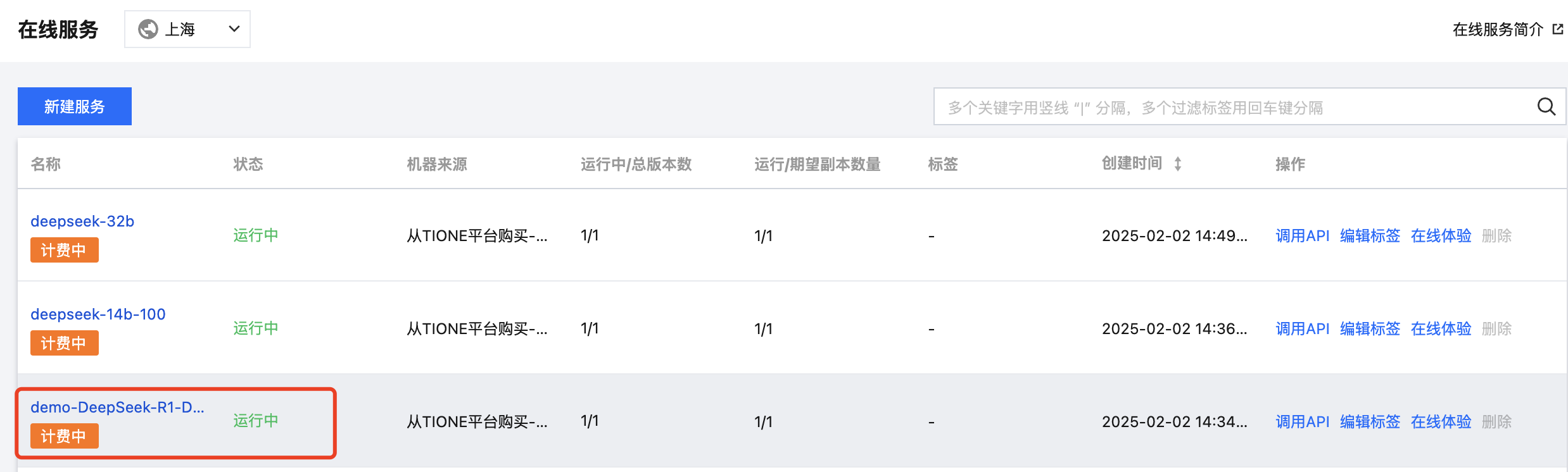
2. 单击列表中的在线体验,进入模型快速体验页面。可通过前端页面直接提问,体验模型效果。
步骤三:调用模型推理 API
腾讯云 TI 平台在线服务模块内置了接口调用测试功能。此外,您还可以使用命令行等工具测试调用 API。测试完成后,您可以以 API 调用方式将模型接入 AI 应用。下文将对模型推理 API 的测试及接入进行示例说明。
方式一:使用 TI 平台内置工具测试 API 调用
1. 在“模型服务 > 在线服务”页面的列表中,单击刚部署的服务的名称,跳转到服务详情页。
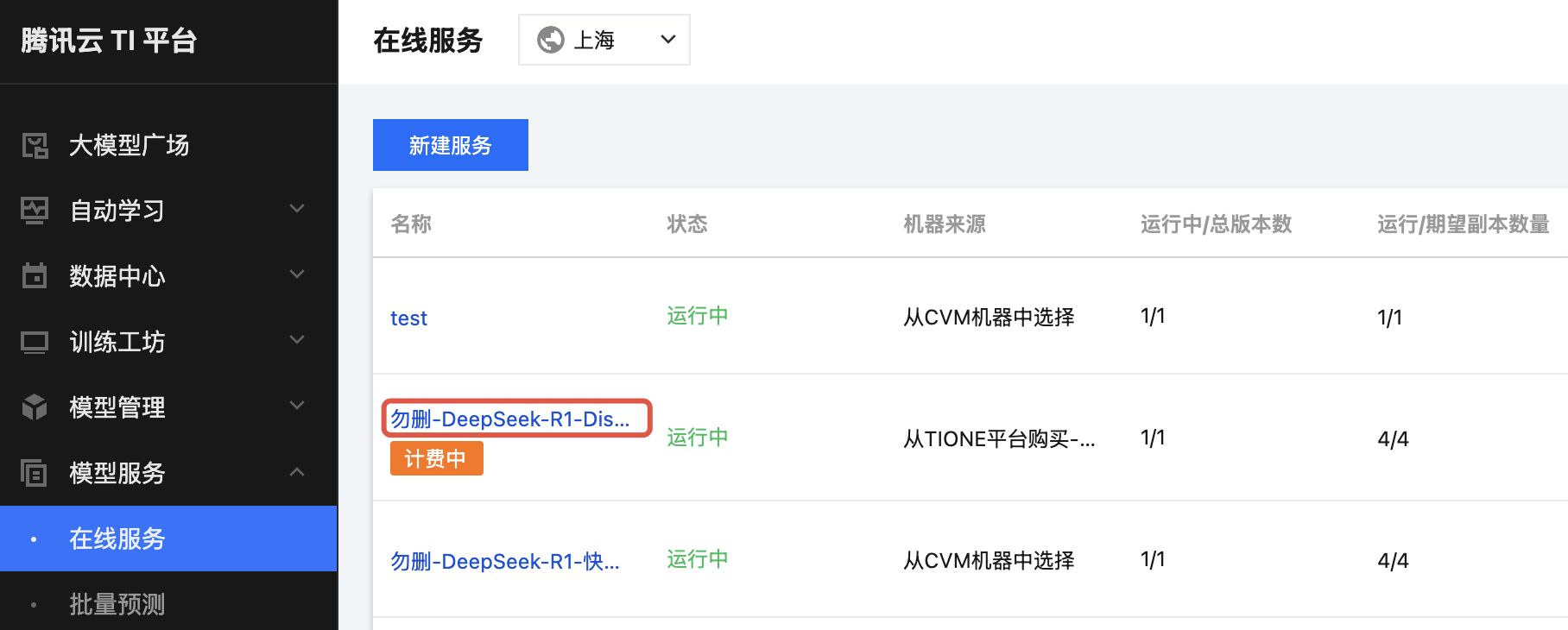
2. 进入服务详情页的“服务调用”Tab,在页面底部可看到“接口信息”版块。
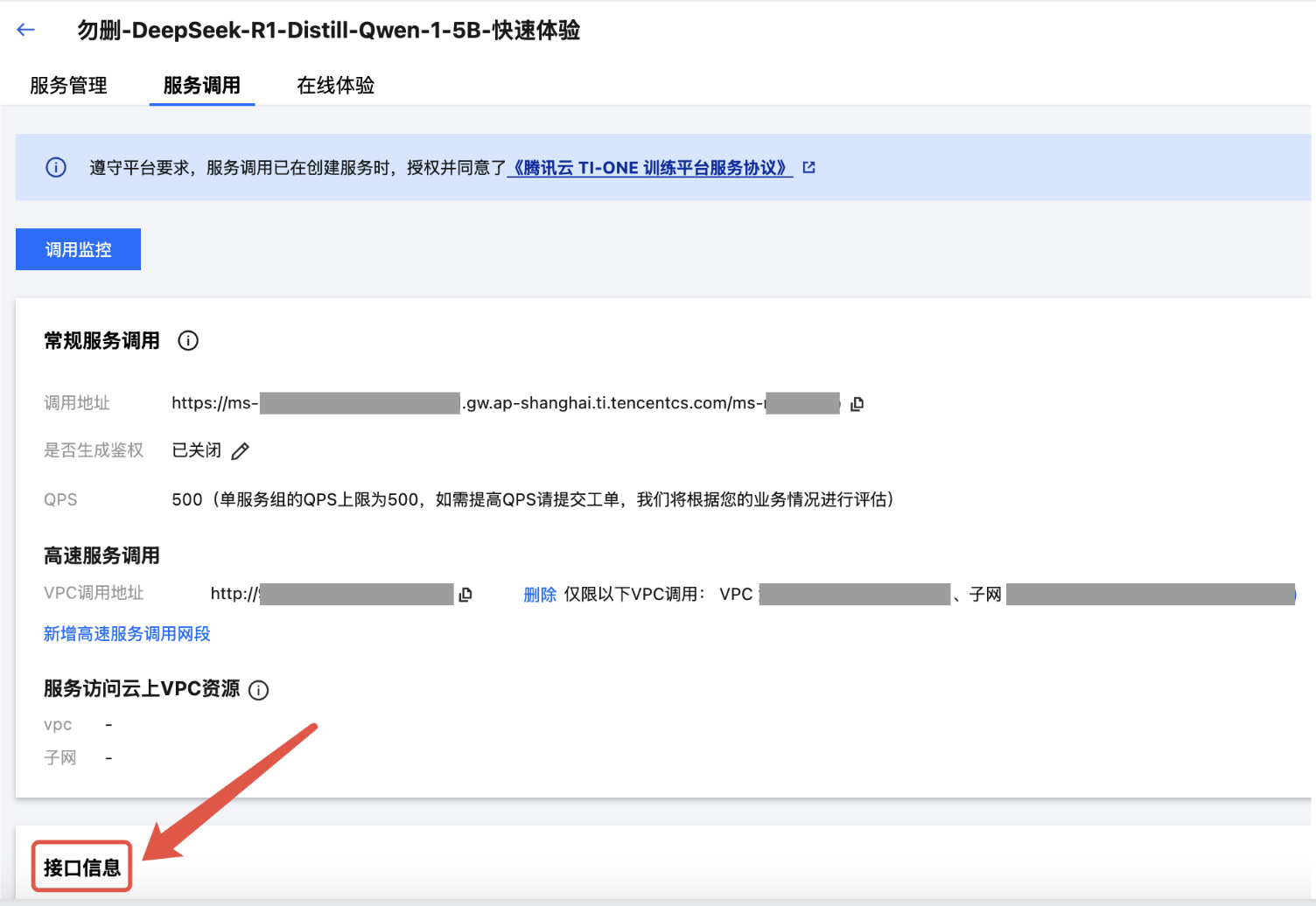
3. 在“接口信息”版块的输入框中,输入接口和请求信息,进行接口测试。
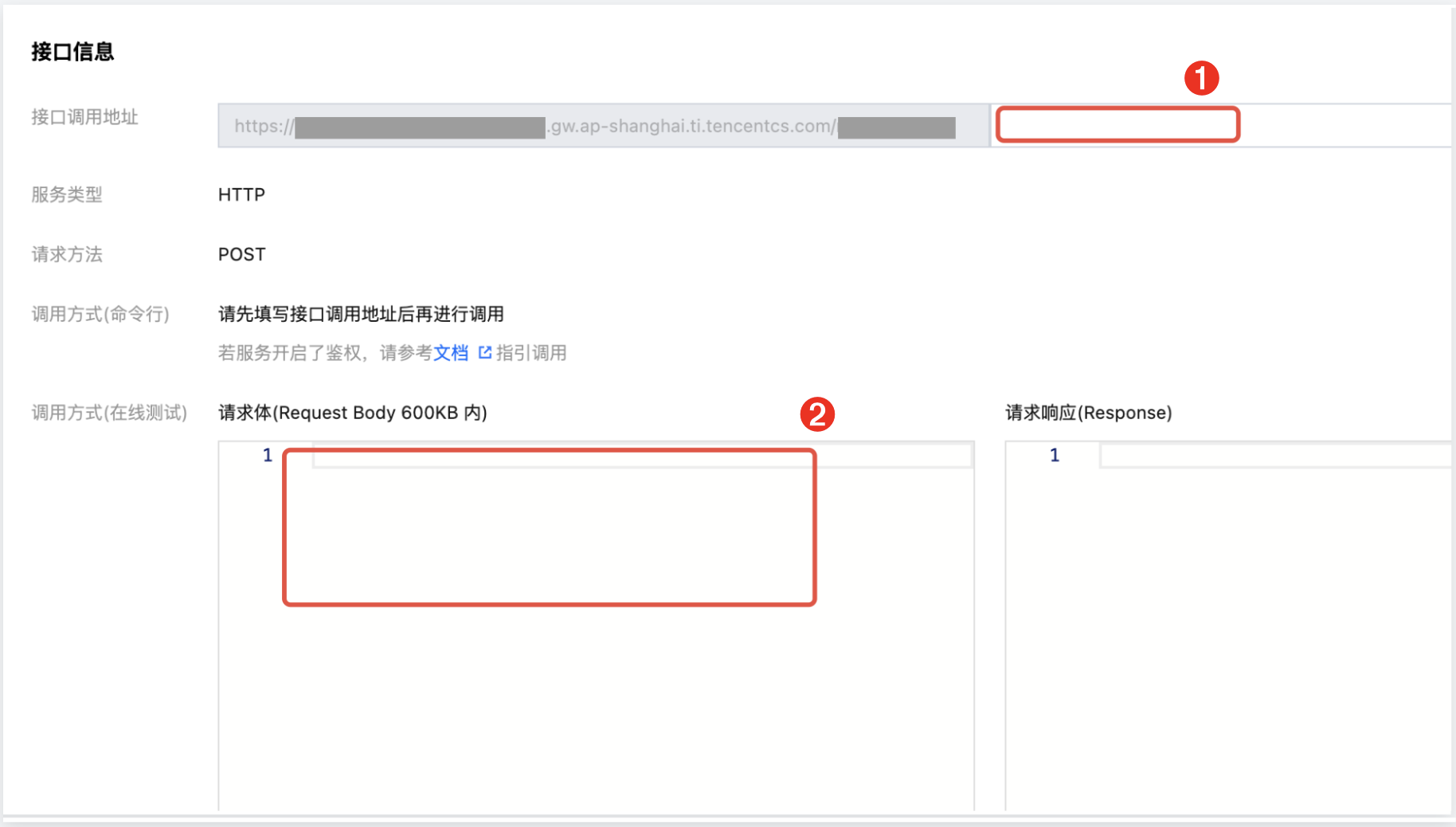
接口名:在上图中位置1处输入接口名,对话接口请填写 /v1/chat/completions。
备注:TI 平台为内置开源大模型配备的推理框架为 vLLM,兼容 OpenAI 接口规范,除对话接口以外的更多接口请参考 vLLM 官方文档。
请求体(Request Body):在上图中位置 2 处输入请求体,Chat Completion 接口的请求体格式请参考下方代码:
{
“model”: “ms-xxxxxxxx”, // 输入服务组 ID,即页面上方“调用地址”的最后一部分,该部分以“ms-”作为前缀
“messages”:
[
{
“role”: “user”,
“content”: “描述一下你对人工智能的理解。” // 输入想提问的 prompt
}
]
}
请求体中需填写的“服务组 ID”即为下图红框中标记的字符串,可看到该字符串以“ms-”作为前缀:

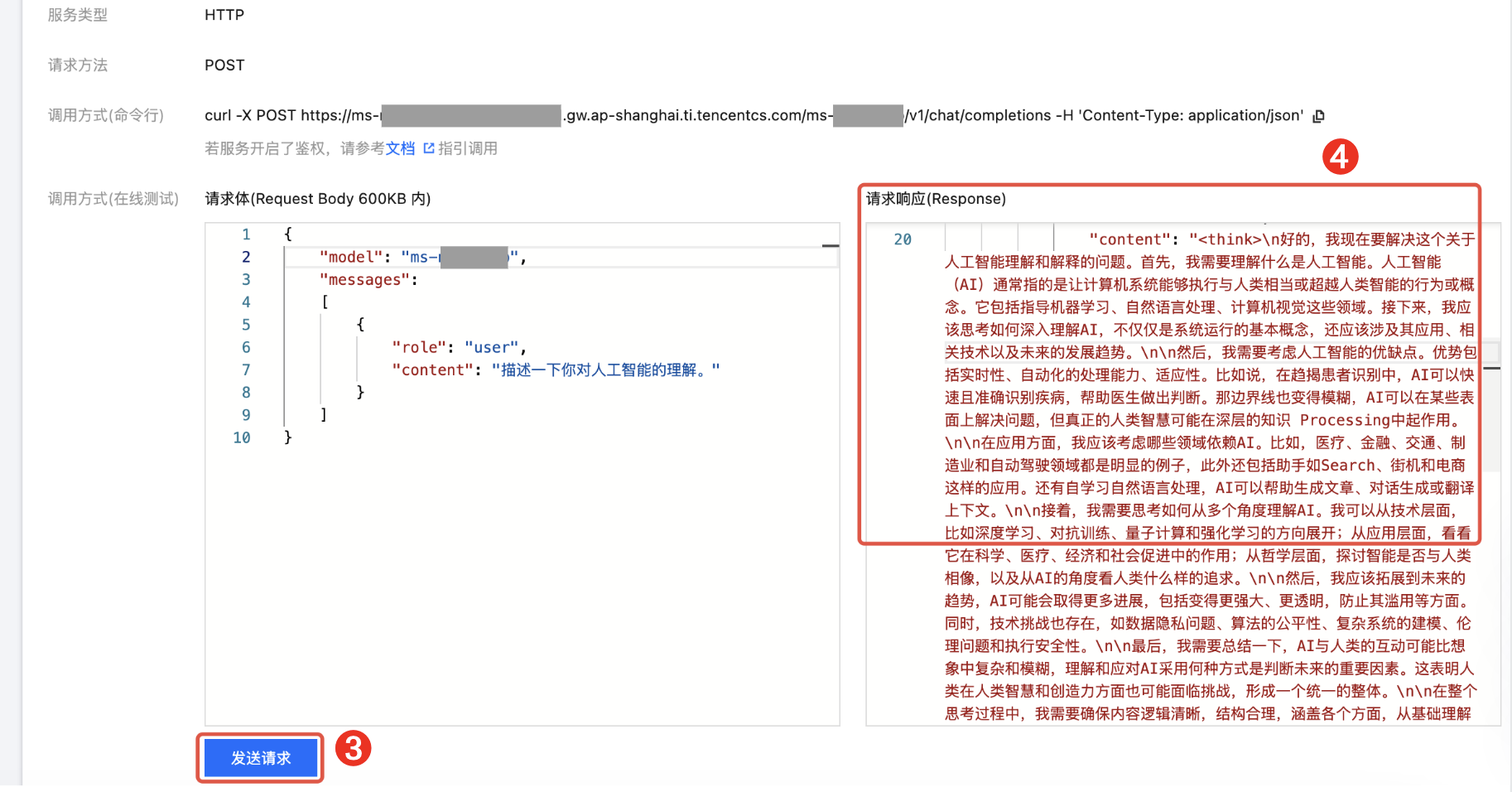
4. 完成信息输入后,单击发送请求,稍作等待,“请求响应”框中将显示模型返回的响应结果:
方式二:使用命令行工具测试 API 调用
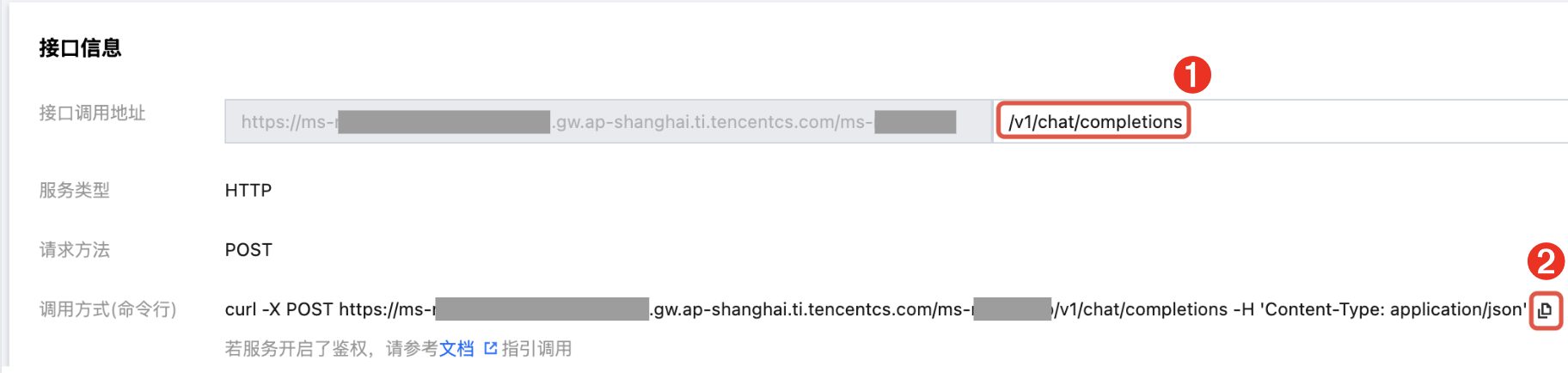
1. 在上述的“接口信息”版块中,在下图位置1处输入接口名。输入完成后,单击位置2处的复制按钮,复制完整的 API 调用命令头。
2. 在命令头最后追加参数 -d’{REQ_BODY}‘,得到完整命令。其中 {REQ_BODY} 为请求体,请按照上文中“使用平台在线测试功能调用 API”的第 3 点给出的格式填写。最终编写成的完整命令应如下方代码所示:
curl -X POST https://ms-xxxxxxxx-xxxxxxxx.gw.ap-shanghai.ti.tencentcs.com/ms-xxxxxxxx/v1/chat/completions -H ‘Content-Type: application/json’ -d'{
“model”: “ms-xxxxxxxx”,
“messages”:
[
{
“role”: “user”,
“content”: “描述一下你对人工智能的理解。”
}
]
}‘
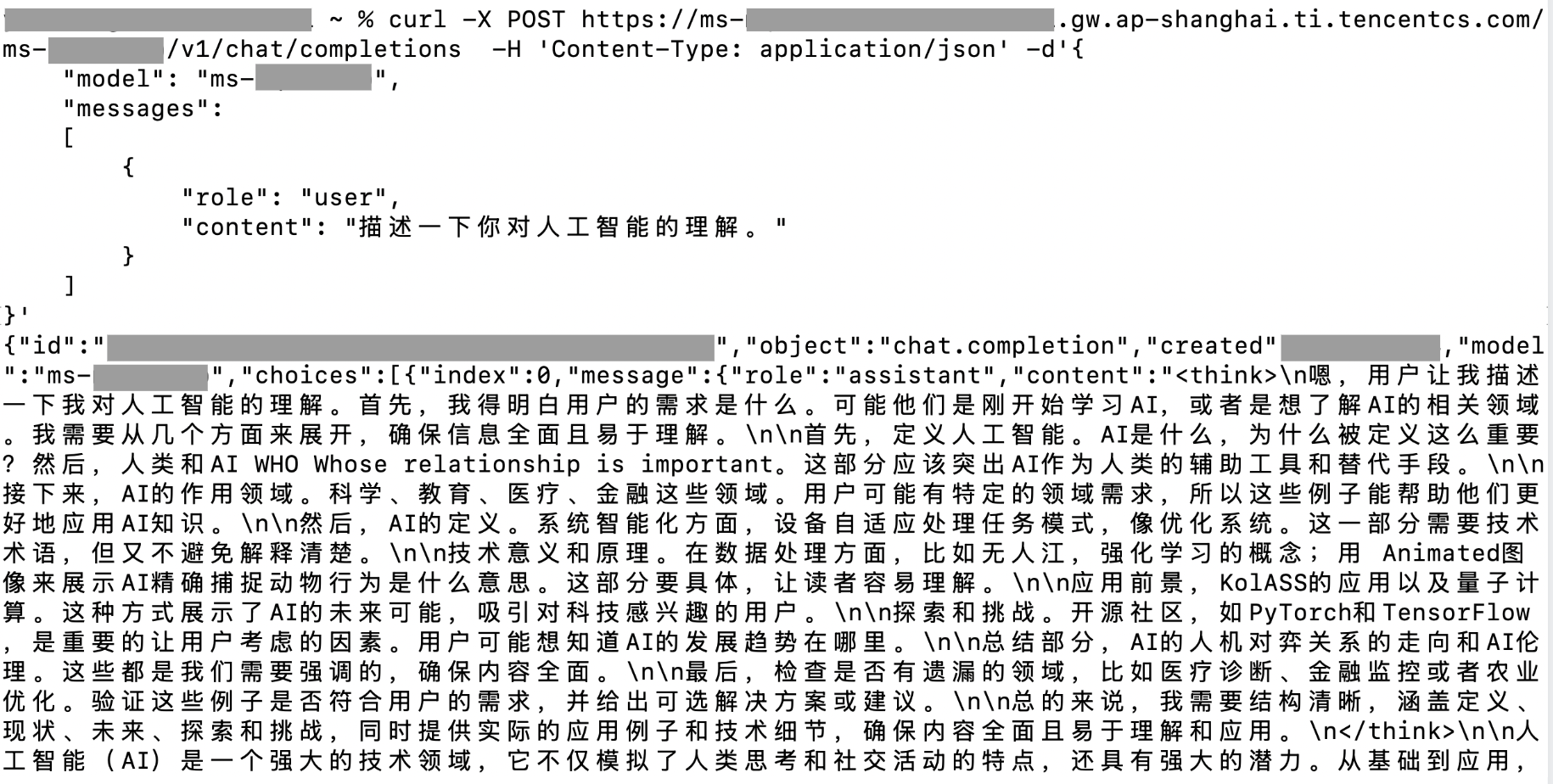
3. 将完整命令输入到已连接到公网的计算设备的命令行工具中并执行,命令行中将返回模型的输出。
方式三:使用第三方应用开发工具调用 API
完成模型部署后,如果您需要在您的 AI 应用中接入已部署的模型服务,可以将服务 API 的信息配置到相关平台或系统中。下文以Cherry Studio为例,介绍如何将服务 API 接入应用中。
Cherry Studio 是一个支持多模型服务的开源桌面客户端,可以将多服务集成至桌面 AI 对话应用中。本文仅以此为例介绍 API 调用。如您需要商用 Cherry Studio,请仔细阅读其开源软件协议。
1. 进入您在 TI 平台已部署模型服务的“服务详情页 > 服务调用”Tab,在页面较上方位置找到“调用地址”字段,并单击最右侧复制按钮复制。
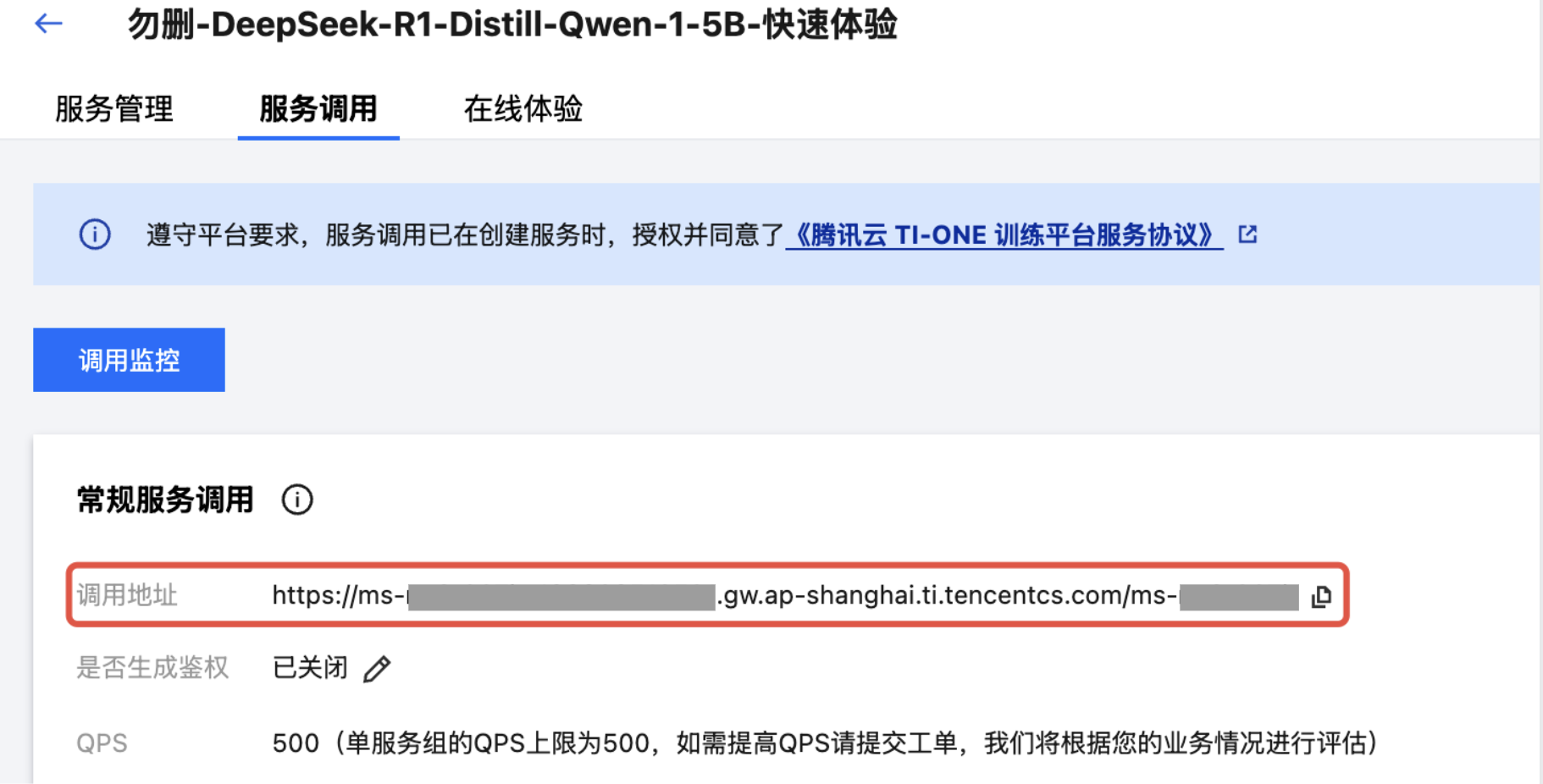
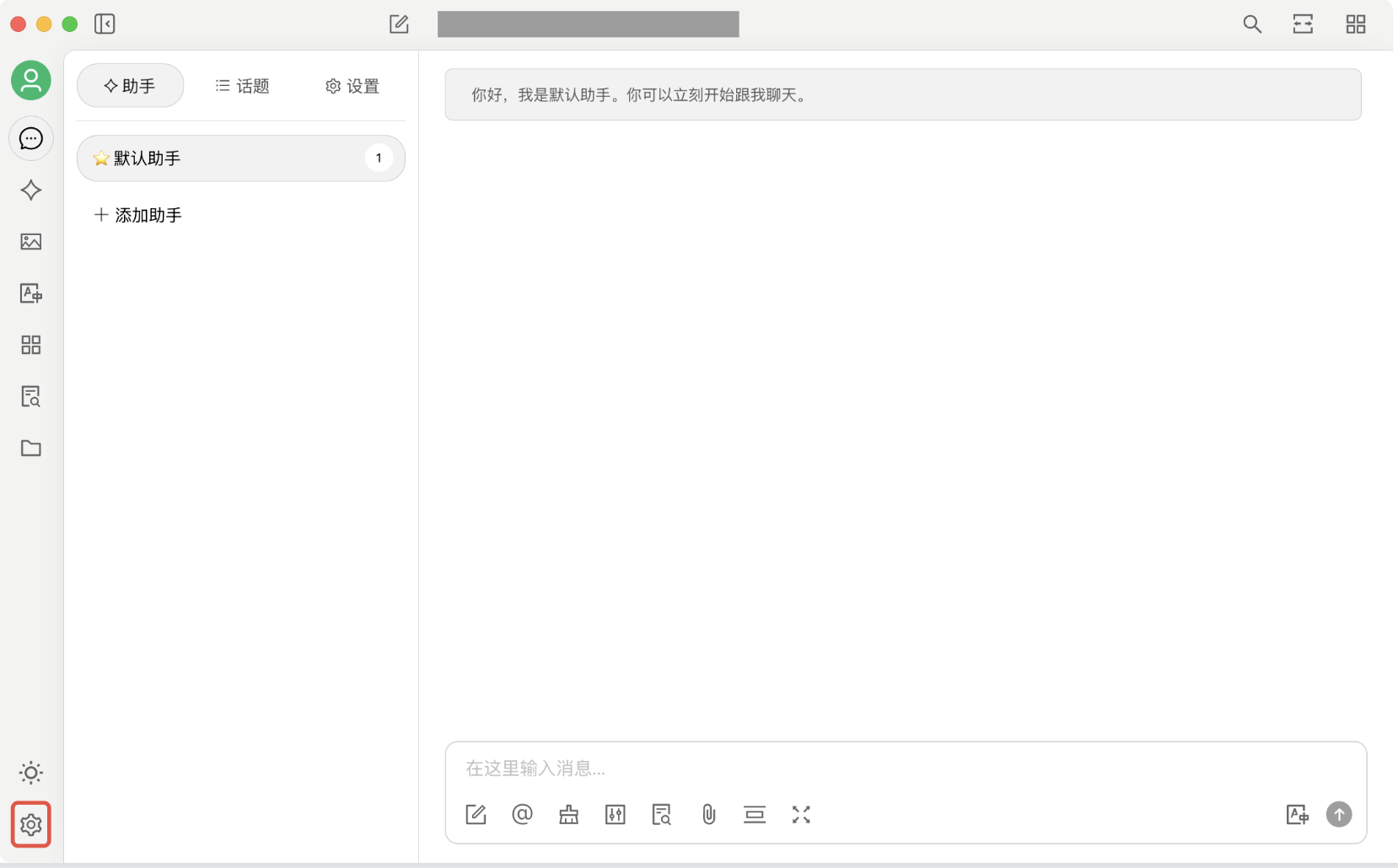
2. 下载并安装 Cherry Studio。完成安装后,打开 Cherry Studio,进入产品主页,并单击左下角的设置按钮,跳转到产品设置页。
3. 进入产品设置页后,单击页面中间下方的添加:
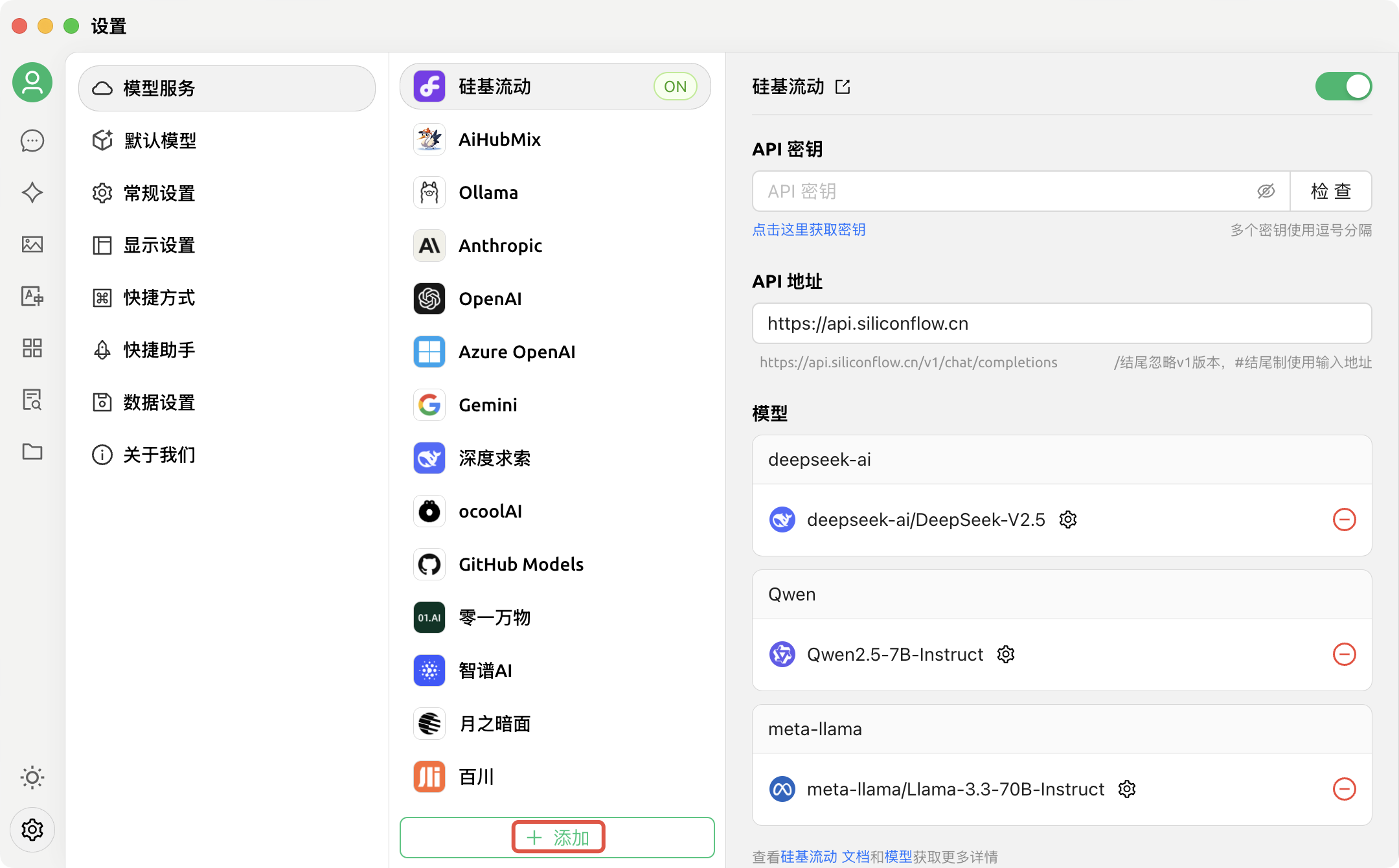
4. 单击添加后,需要在弹出的“添加提供商”对话框中输入信息,其中,“提供商名称”可自由填写,提供商类型需选择“OpenAI”,填好后单击确定:
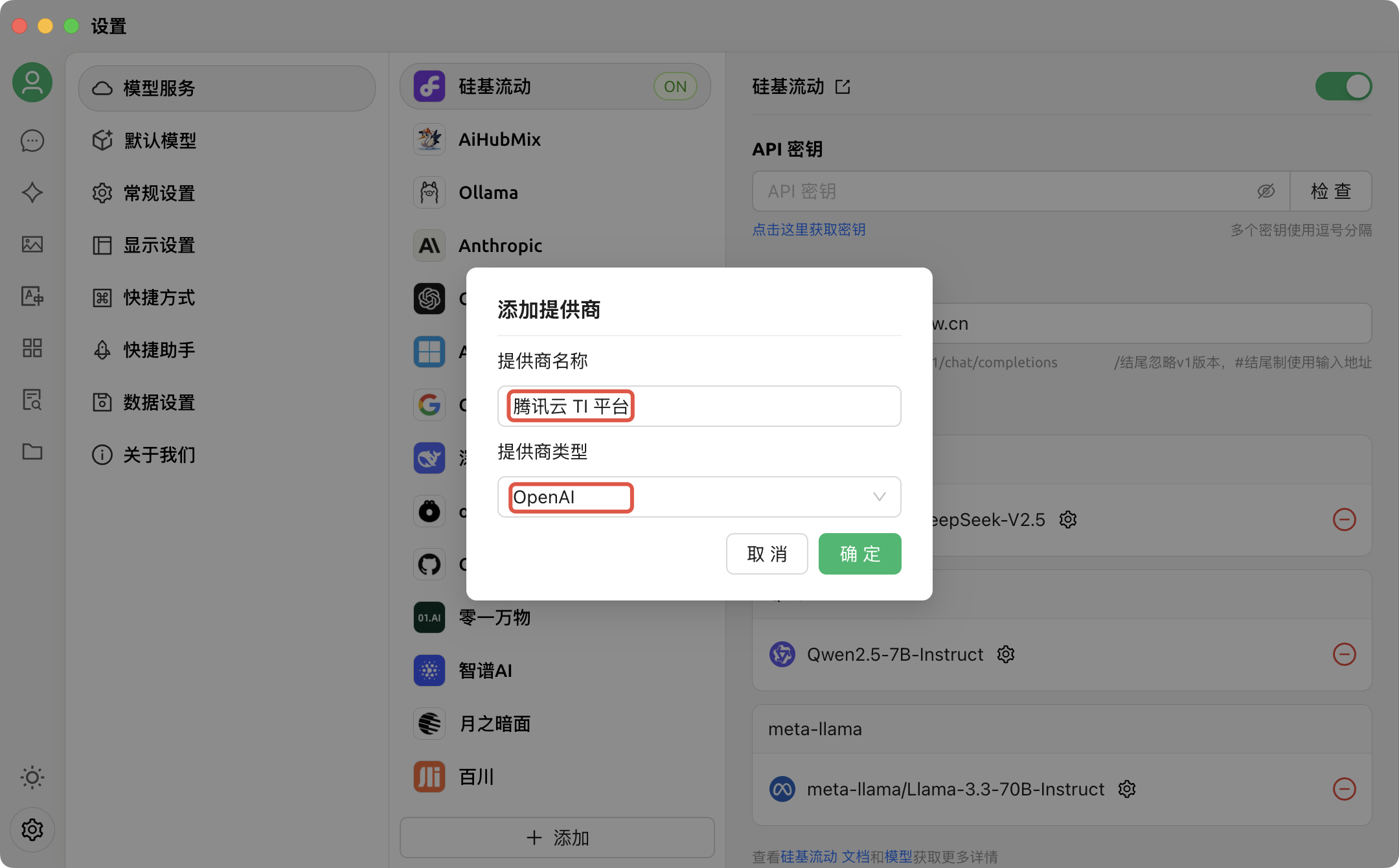
5. 按照第4点要求成功添加提供商后,将自动跳转到该提供商的配置菜单,本文中示例为“腾讯云 TI 平台”。请注意:TI 平台当前的鉴权方式和 OpenAI 有所不同,因此仅支持以未开启鉴权方式将 API 接入 Cherry Studio。在未开启鉴权的前提下,进行如下配置:
API 密钥:可任意填写,但不可以不填。
API 地址:粘贴第1点中复制的调用地址。
配置完成后,单击下方“模型”版块的添加。
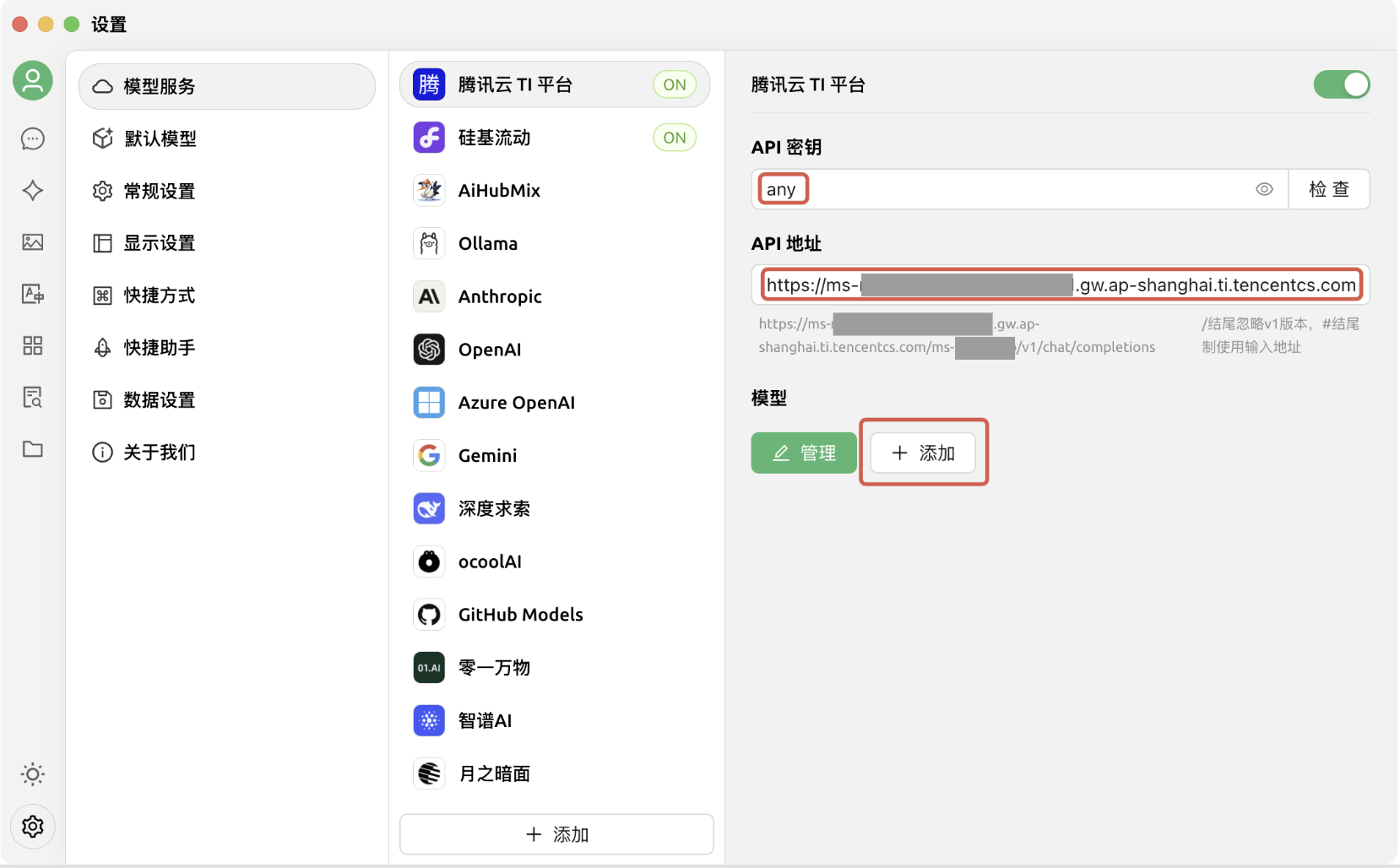
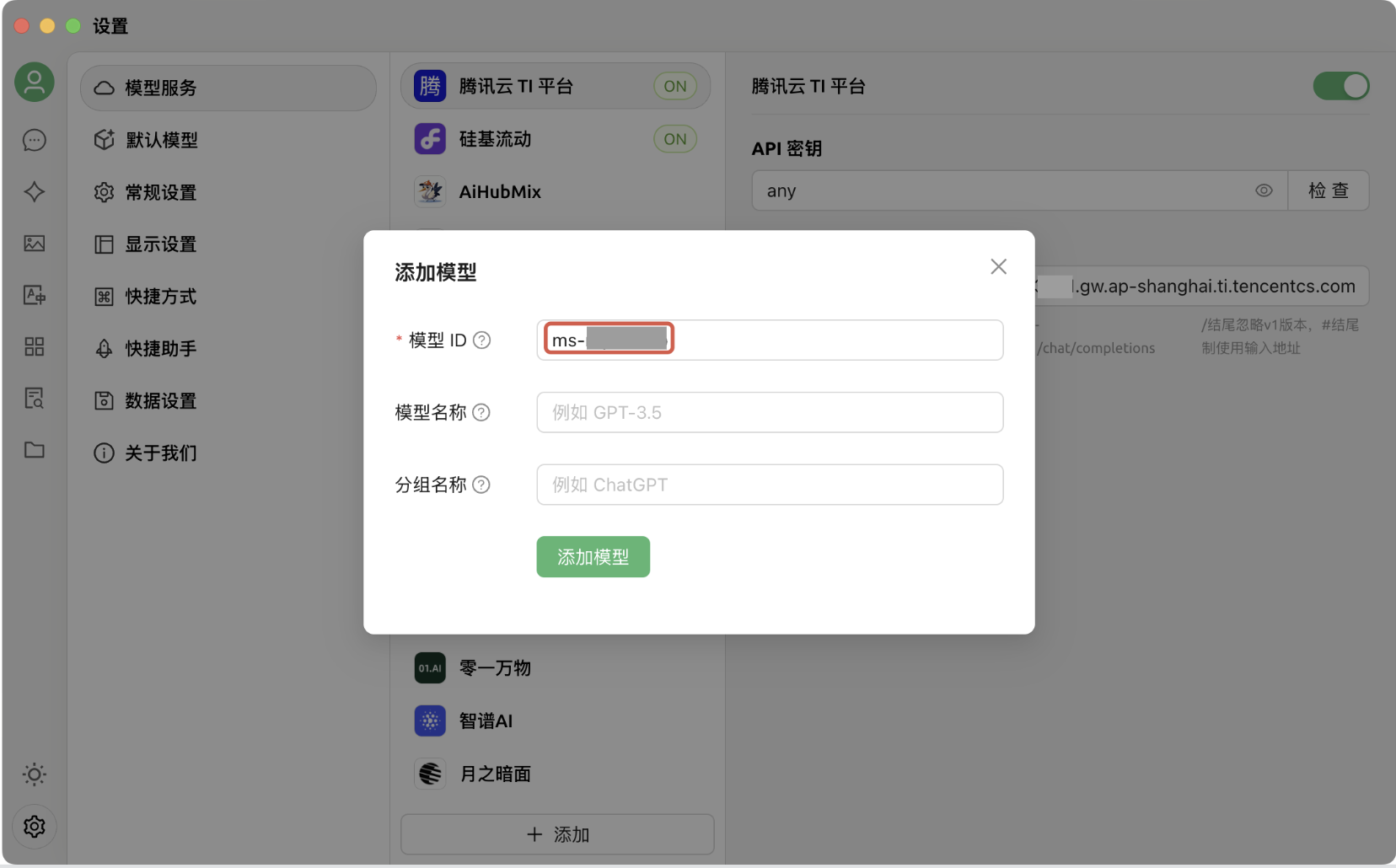
6. 单击添加后,将弹出“添加模型”对话框,在对话框中输入要求的信息。其中,模型 ID 需配置为 TI 平台已部署服务的服务组 ID(获取方式见“使用平台在线测试功能调用 API”第 3 点,该字段以“ms-”作为前缀),接着单击添加模型:
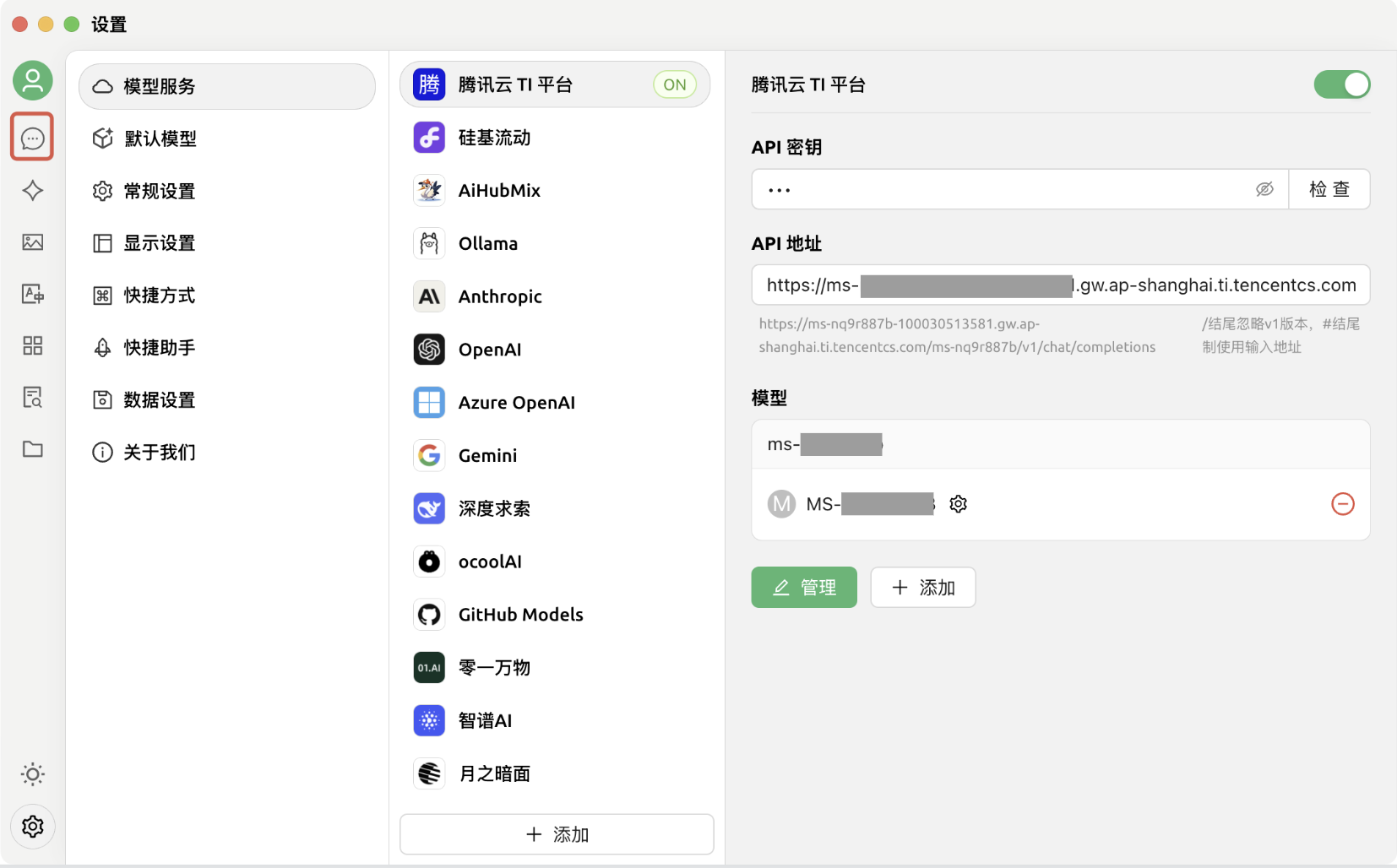
7. 按照第6点的要求成功添加模型后,单击左上方对话按钮,回到对话页面:
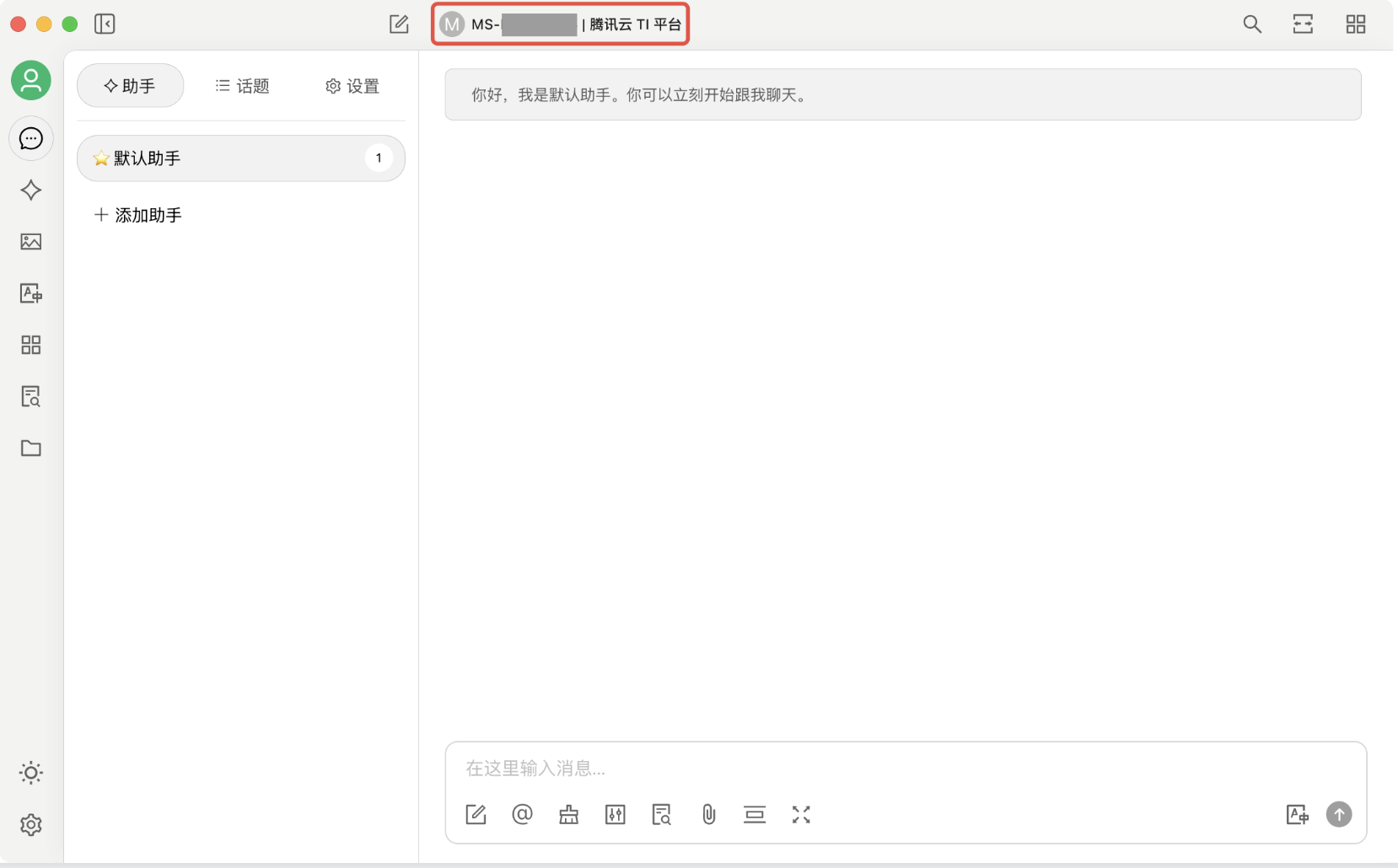
8. 单击对话页面顶部的模型选择按钮,单击后弹出模型列表,选择刚刚添加的模型:
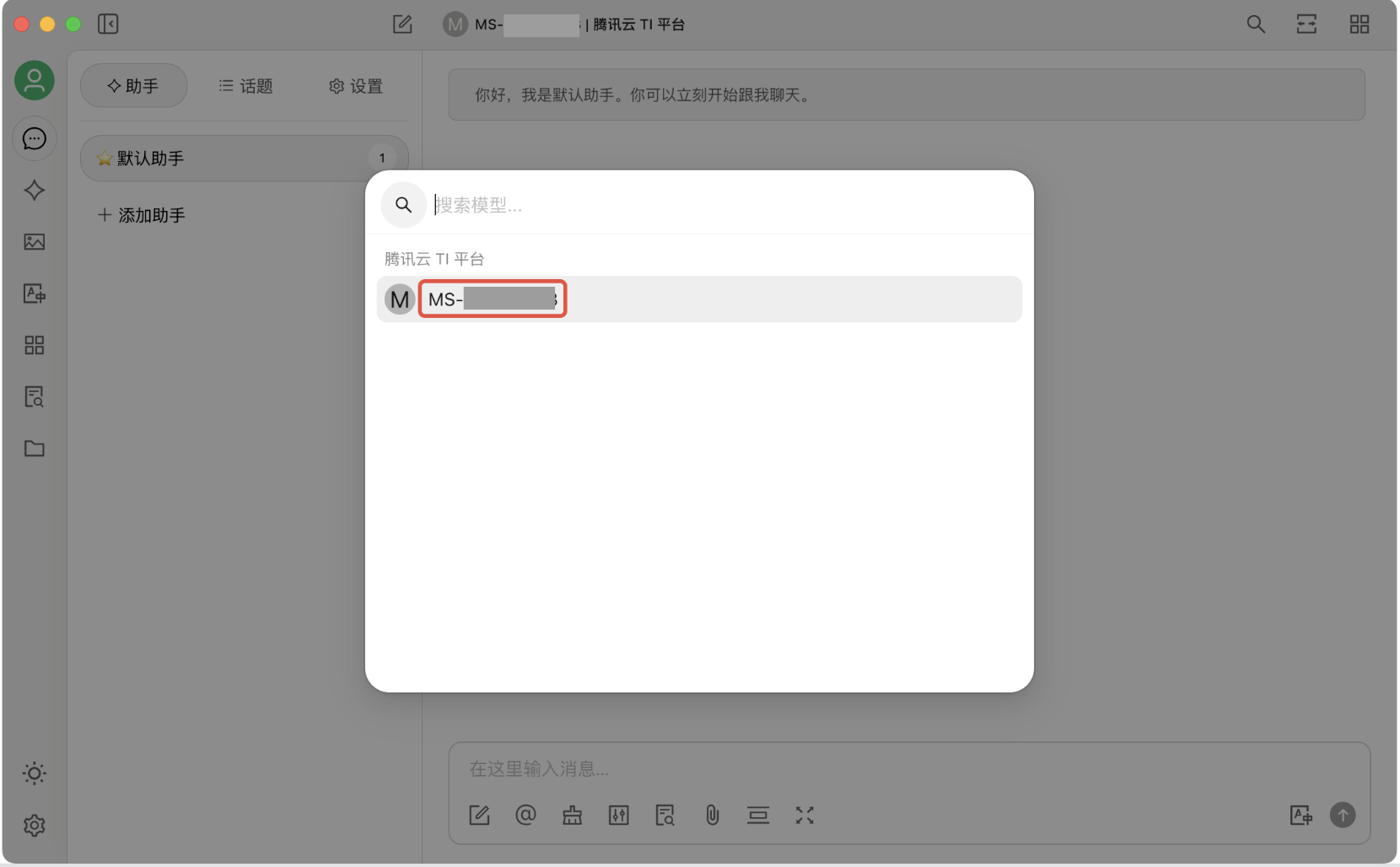
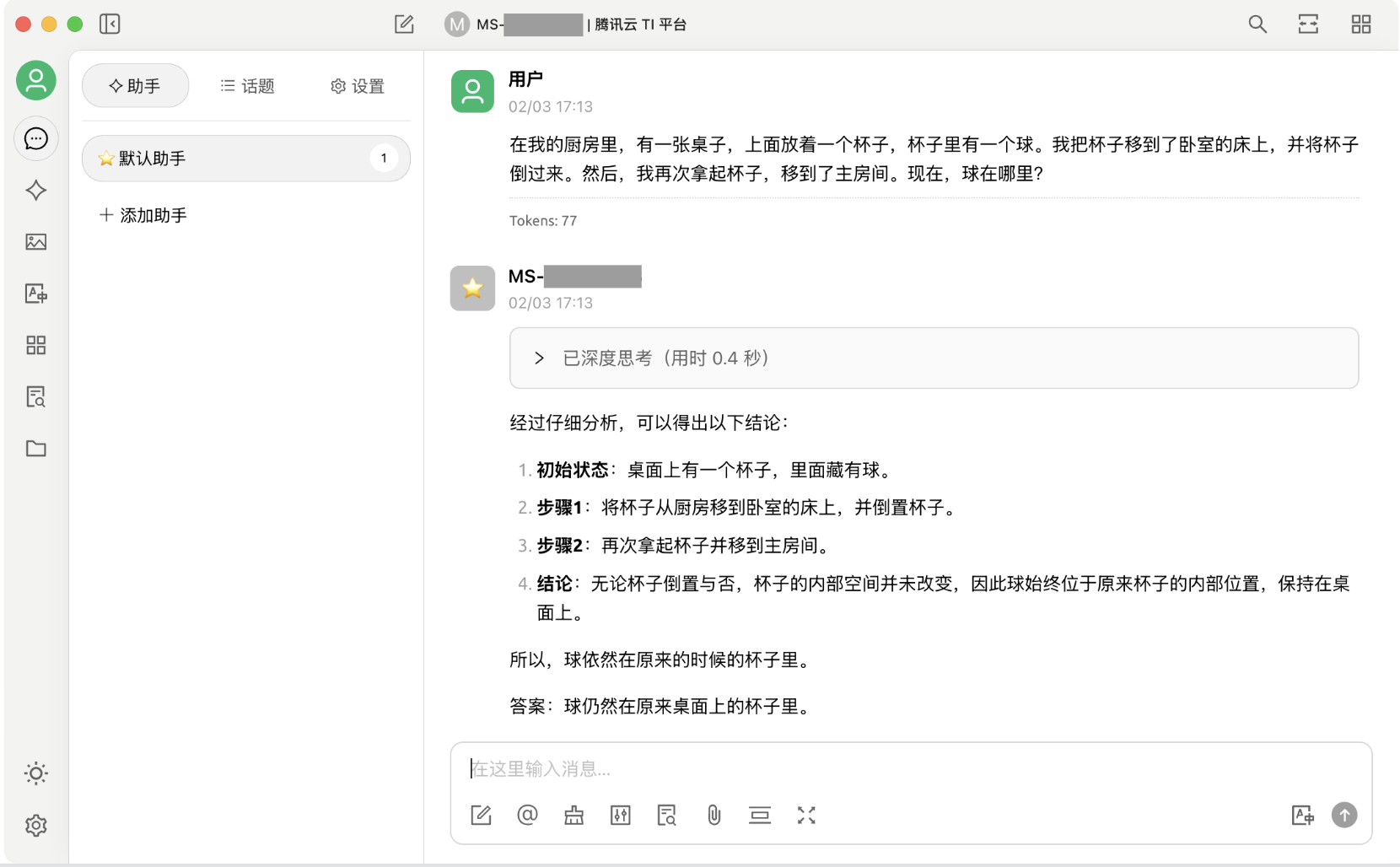
9. 现在,可以通过 Cherry Studio 和在 TI 平台部署的模型进行对话了:
步骤四:管理推理服务
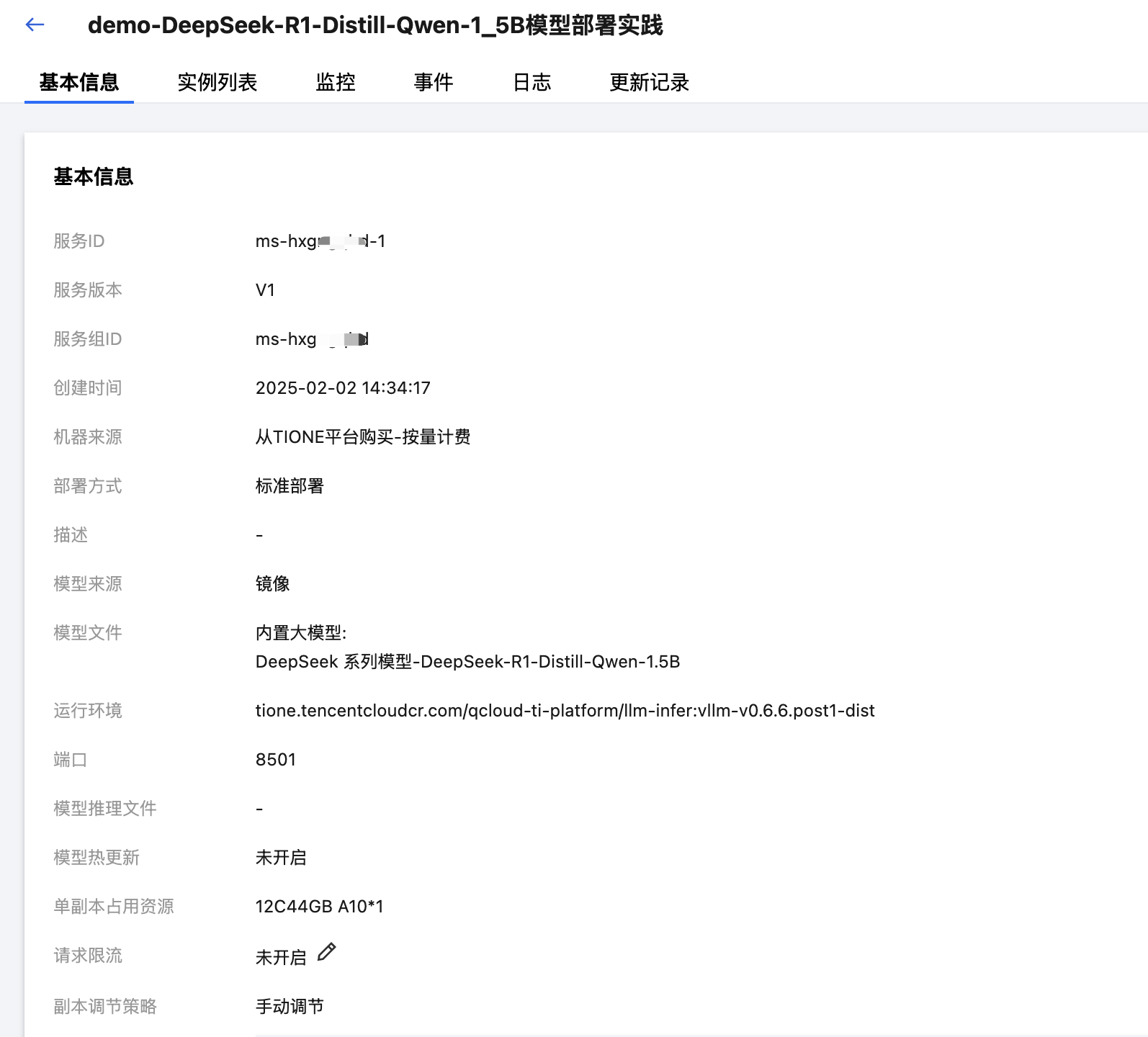
您可以通过访问“模型服务 > 在线服务 > 服务详情”页面查看并管理推理服务。包括但不限于:停止/重启/删除服务、查看服务配置信息、实例列表、监控图表、容器事件、日志、更新记录等。详细操作指引可参考在线服务运营。
不同模型部署的注意事项
大小模型的效果对比
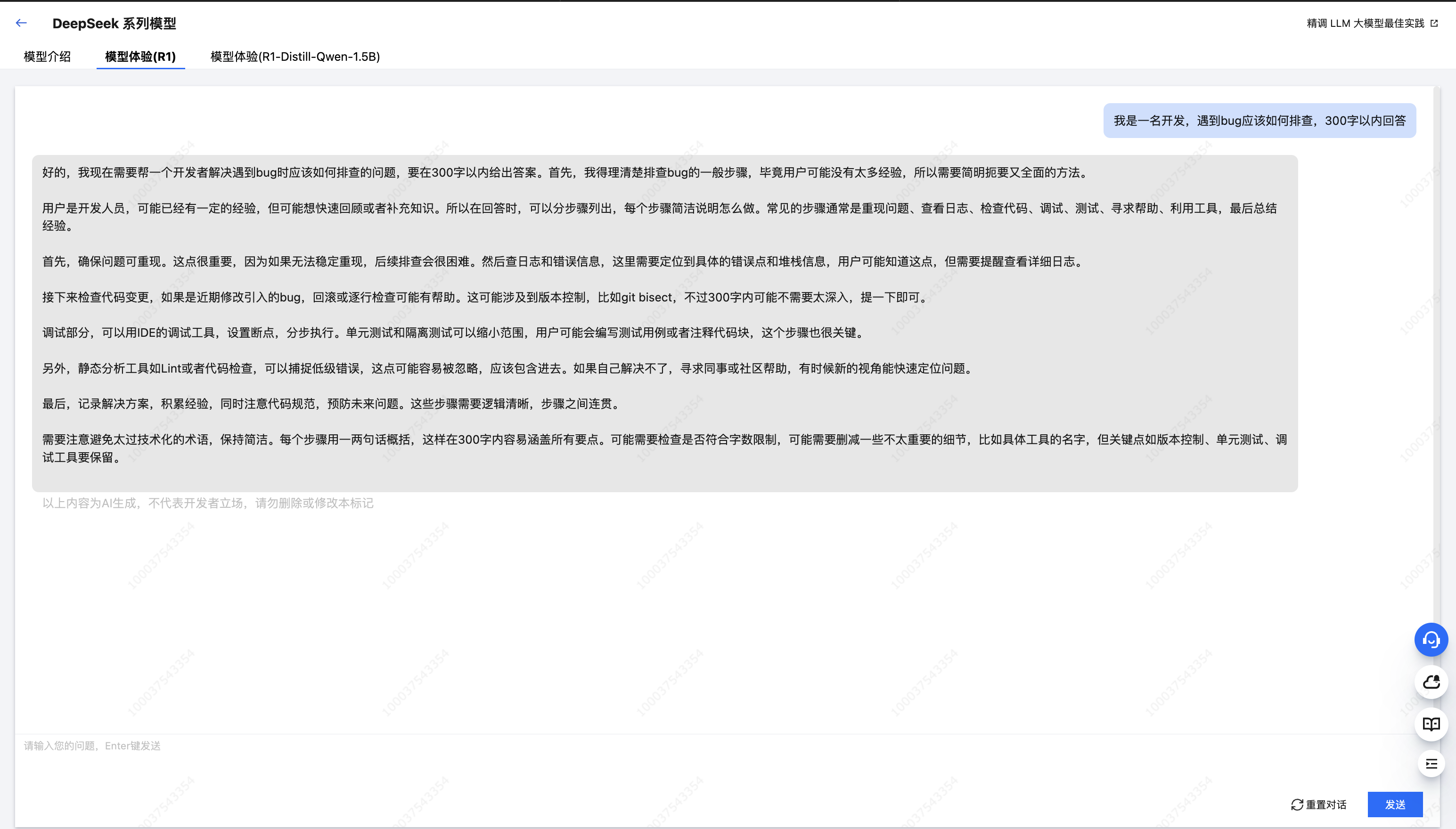
基于已部署的“DeepSeek-R1-Distill-Qwen-1.5B”和“DeepSeek-R1”模型服务,我们尝试使用一个相同的问题,简要对比一下大小模型的推理效果。
问题输入
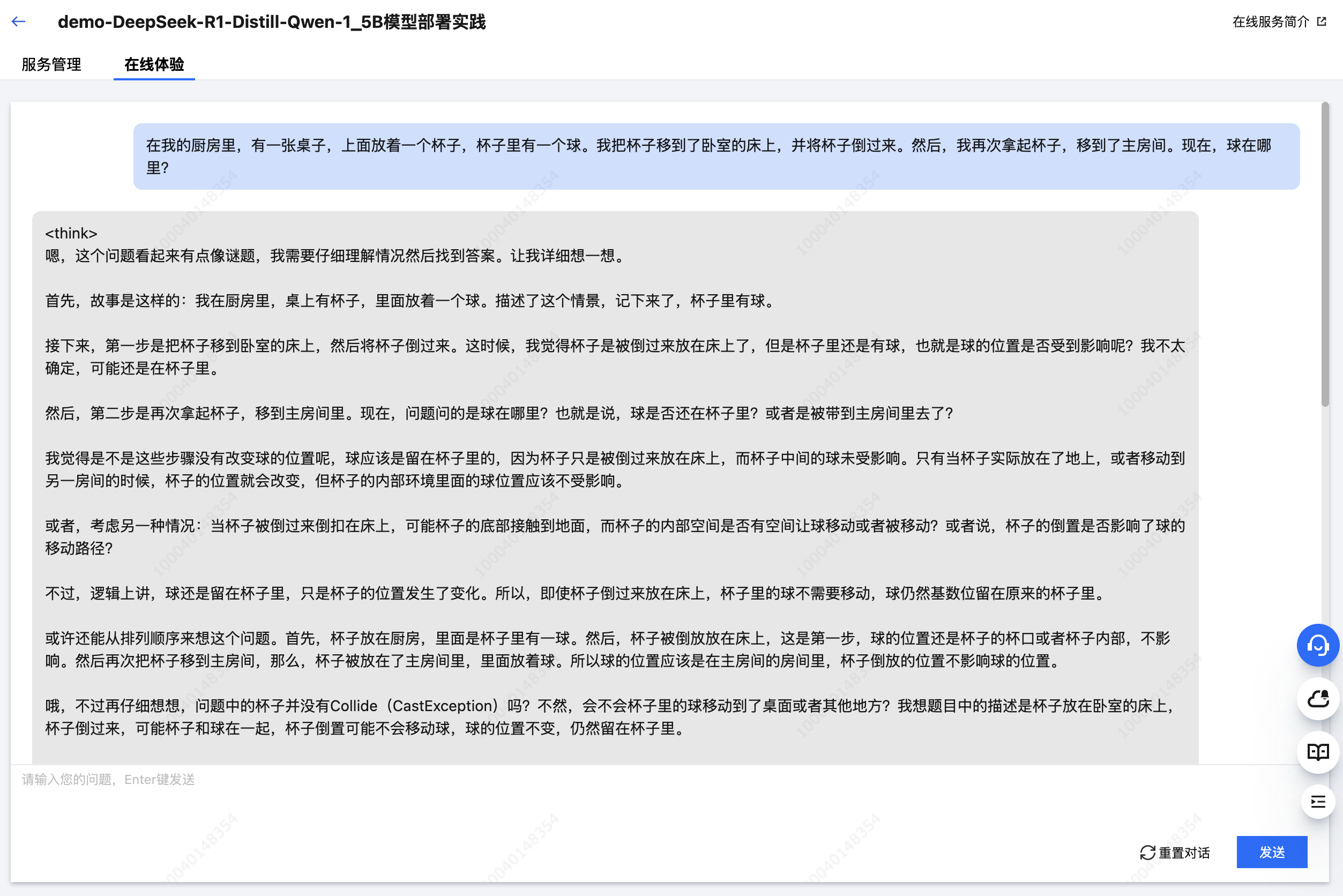
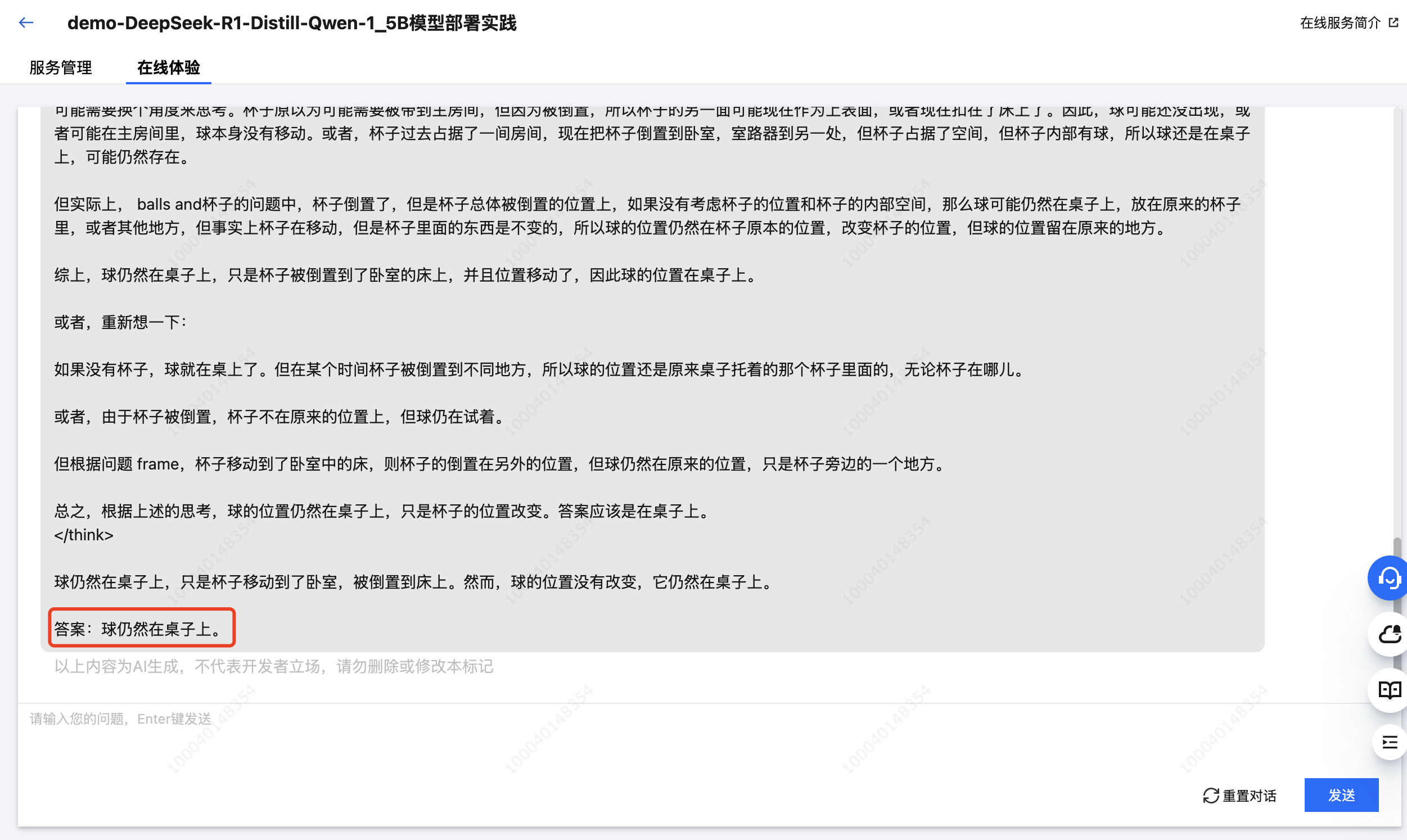
在我的厨房里,有一张桌子,上面放着一个杯子,杯子里有一个球。我把杯子移到了卧室的床上,并将杯子倒过来。然后,我再次拿起杯子,移到了主房间。现在,球在哪里?
大小模型效果对比
|
对比范围
|
DeepSeek-R1-Distill-Qwen-1.5B
|
DeepSeek-R1
|
|
截图示例
|
 |
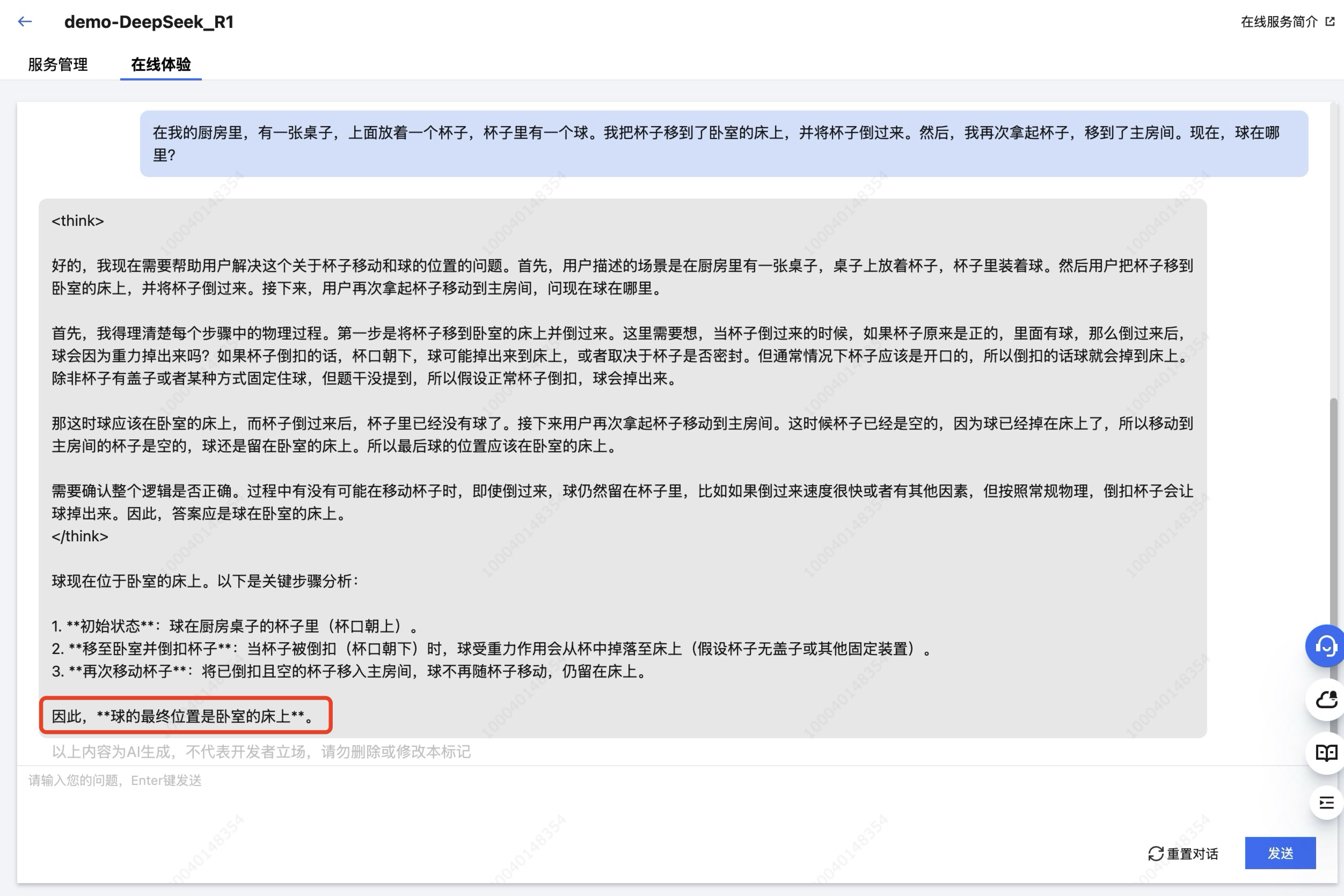 |
从响应结果中可以明显看出,拥有更大参数量的 DeepSeek-R1 模型在推理效果上更胜一筹,其正确推理出了杯子倒扣时球会掉出并留在床上,即使杯子随后被移动至房间。而参数量较小的 DeepSeek-R1-Distill-Qwen-1.5B 模型仍然认为球在杯中。
另一方面,相比 DeepSeek-R1 模型,更小参数的 DeepSeek-R1-Distill-Qwen-1.5B 模型的响应速度更快、占用资源更少、部署时长更短,在处理较为简单的任务时,仍是不错的选择。
其中,DeepSeek-R1-Distill-Qwen-1.5B 的部署时长预计为1-2分钟,DeepSeek-R1 预计为9-10分钟(模型需预加载到节点的本地数据盘中)。
本文由阿里云优惠网发布。发布者:官方小编。禁止采集与转载行为,违者必究。出处:https://aliyunyh.com/225325.html
其原创性以及文中表达的观点和判断不代表本网站。如有问题,请联系客服处理。

